


What Goodreads could have been
And a prototype of something different...

Apparently 88,000 people read the last post here. It went to the top of HackerNews, was featured in Morning Brew, Startup Digest, and most amusingly, Money Stuff. Basically, it was a bit crazy. Also, more than 100 people decided to subscribe, which feels like a pretty big vote of confidence after just 1 post. So I guess the pressure’s on for this one…
Last weekend I was recommending books to 3 million strangers on the internet. It’s not a situation I’ve been in before. Setting it up, while definitely easier than selling an NFT, wasn’t completely straightforward. I ended up handwriting HTML and CSS to show book previews in a way I thought made sense.
This gave me an inkling of an idea. And thinking about this gave me an excuse to do 2 things:
Try out Supabase to see if I could built an entirely new app in a weekend
Really go to town on why I don’t like Goodreads.
I don’t want to bury the lede. If you don’t want to read a longish article and just want to try something out, you can sign up to the prototype here: https://copybooks.app.
Recommending books on the internet
On istheshipstillstuck.com, this is what I ended up with when I tried out affiliate marketing:

I wasn’t particularly happy with it, but I didn’t have time to make something better. Firstly, the book list (and its order) was hardcoded. Every time I wanted to change the selection, I had to change my code and redeploy the whole website. That’s the main reason why I ended up with so many commits for what was quite a simple site:

The second “issue” was that this was just me imposing my ranking on the world. It would have been far more interesting if the ranking could have dynamically changed based on which books people were actually clicking on.
Finally, I managed to localise these links so that people with their computer’s language set to “en-gb” would get shown Amazon UK links, while others would get Amazon US links. However, this didn’t always work — a lot of people in the UK just use the default American language settings. It also didn’t account for people not living in the UK or in the USA, which was actually quite a lot of traffic:

I couldn’t find a useful widget that had all this built in, so I had to make do. But what really confused me was: why on earth doesn’t Goodreads do this?
They’ve made a half-hearted attempt — but you can’t add an affiliate code, you can’t add comments and you can’t easily choose the order:
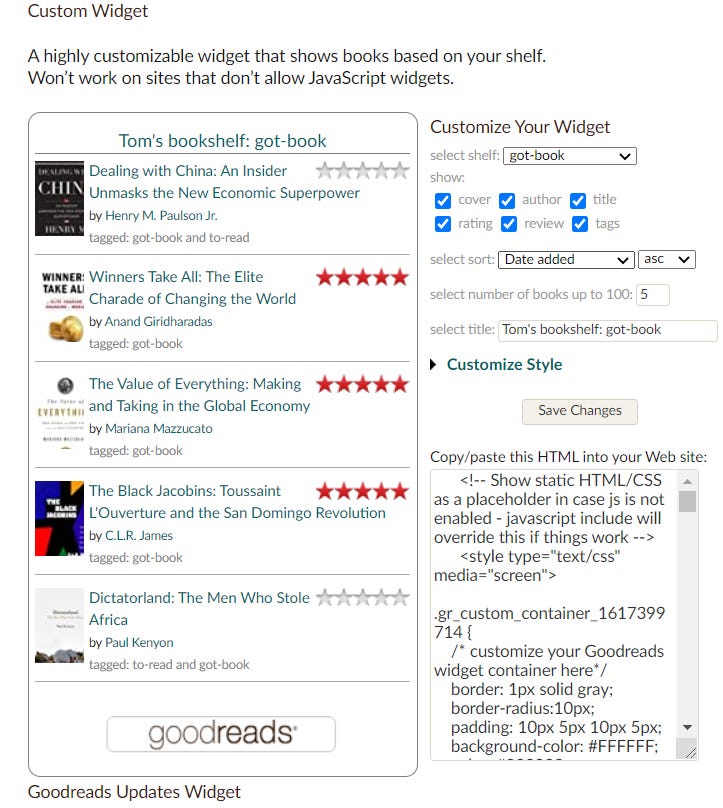
A week later and I’ve been thinking a lot more about how and why Goodreads screwed up…
Goodreads

Critiques of Goodreads are 10-a-penny. Most them bang on about on how the UI is dated, how parts of the site are buggy/broken or how the content moderation is a misery for authors. But if that were truly a death sentence for the success of a product, someone ought to write to Craig Newmark, Jeff Bezos or Mark Zuckerberg. Make sure to address it to their butlers.
Goodreads isn’t “broken” because it’s difficult to use. Goodreads never achieved what it set out to do in the first place:

The focus is on finding and sharing. But virtually no one uses it for that. If you ask people how they actually use the site, they say this:
I do find it useful, but not entirely for the way it's intended. The social part of Goodreads is the least important thing to me. I don't belong to groups or seek out friends at the site or utilize any of the recommendations or lists. Mostly it's an organizational tool to keep track of what I've read .
I mostly use it as a glorified list of the books I want to read in the coming time (I LOVE making lists).
I pretty much completely ignore the social-media aspects of the site with the possible exception of occasionally scanning a list or two.
I like it as a personal record, of books I read and how I felt about them.
I absolutely detest it as a social media. All you ever see are people posting gifs and extreme reviews long before the books are published. The sheer amount of "I refuse to read this book and it gets 1 out of 5 because nothing can be as good as THE hunger games" are rampant, and even worse they tend to end up as top reviews.
Goodreads wants to be a social network. For most people, Goodreads is a bookmarking tool. That’s why the embed widget wasn’t what I wanted. It was just a public facing progress tracker, not a tool built specifically for sharing books.
Of course, the site does have its fun moments…

Though if the top Goodreads moments start to sound like they ought to be on Twitter… segue time…
A theory of social networks:
I recently read an interesting blog post about social networks called “Status as a Service”. It talks about how social networks compete on 2 things: Social Capital and Utility. By Utility it meant “using this app makes my life easier” (think Steve Jobs’ “bicycle for the mind”). Social Capital essentially means to what extent does the app feel a bit like this:
Here’s a few examples:
Messaging apps (Skype, Whatsapp, Messenger etc.) are high utility, low social capital. Much better than shelling out 12p credit per text, but you can’t really get followers/likes or meet new people.
Facebook is apparently high social capital, low utility. It’s basically useless for your life, but if you post your engagement photos you get lots of likes.
High utility, high social capital apps basically only exist in China: think WeChat.
This is Goodreads, on a graph:

On Goodreads, there are a few people fishing for likes with their reviews, but generally Goodreads doesn’t really have any Social Capital. People just use it to make their life easier.
This is extremely weird!
How we talk about books:
Outside of Goodreads, people talk a lot about their favourite books, and we constantly use them to make judgments about people. If you walk into someone’s house and there’s a copy of Infinite Jest on their table, you know what you’re dealing with:

Likewise, if someone’s book shelf is filled exclusively with Jeremy Clarkson, Stephanie Meyer or Dan Brown, you’re probably making a different kind of assessment. And if it’s exclusively Jordan Peterson? Run.
More generally, recommending a good book gets you some social brownie points. And in a remote-working world, woe betide the talking face with a poorly judged bookshelf:




This is such a big deal that you can hire a Zoom bookcase consultant, or buy “books by the yard” purely for decoration.
But Goodreads doesn’t seem to want to engage in any of this. They seem quite happy to just be a fairly useful bookmarking tool. If you ever see someone offering their book recommendations, they won’t be using Goodreads to do it. They’ll create a new page on a website, write a Twitter thread or write a blog post.
What went wrong?
In my view, Goodreads made 2 poor product decisions:
Copying/building on Facebook
Combining recommendations and progress-tracking
You can’t really blame Goodreads for copying Facebook. When the site was founded in 2007, Facebook was the only game in town. Everyone and their dog was building the “Facebook, but for cats”. But that decision has limited Goodreads. While reading is sometimes a group activity (think book clubs or primary school), it often isn’t. To be completely honest, I don’t usually care what my friends are reading. However, I do read the recommendations of people on the internet — I’m not friends with them on Facebook, I follow them on Twitter. I think it makes sense. I generally follow people on Twitter because they are interested in the same things as me, which isn’t necessarily true about my actual friends (nor would I want it to be, I think that would make life quite boring).
Combining recommendations and bookmarking is a stranger decision. For Goodreads to be most useful, I need to use it to keep track of all the books I’m reading — but that means recommendations are an unfiltered mess. In a world where people buy “adult cover Harry Potter” books and where 50 Shades of Grey sold twice as many e-books as physical copies, do people really want their bookmarking tool to be the same as their recommendation platform?
Also, maybe I’m just not interested in everything you’re interested in? I like reading books about football (the Fever Pitch kind), about shipping, about tech, economics, business and the occasional historical fiction. I’m guessing you’re not interested in all those genres. But, by encouraging people to create shelves of simply “Read”, “To-read” and “Currently Reading”, grouped only by the star review you give them, Goodreads bundles all this stuff together.
What is copybooks.app?
On Hacker News, there’s a meme: “I could build that in a weekend”. This is my attempt at transubstantiating that meme (it is Easter after all). Predictably, it was a bit more difficult than I thought, so I didn’t manage to get as much done as I’d hoped. However, in true “building in public” style, I thought I’d put out what I’ve got and see what happens.
Essentially, it lets you create a set of book recommendations and then share them:

In the same way Goodreads rips off Facebook, copybooks “draws inspiration from” Twitter. All the recommendations are public. I’m also working on building in a Twitter integration so you can see recommendations most relevant to your interests. Getting back to the original point, it also has a nice embeddable widget for blogs/websites:

It’s not looking to be a straight replacement for Goodreads. There’s no bookmarking, there’s no 5-star reviews (it has rankings instead) and it doesn’t have a list of every book under the sun. Hopefully though, it will have an interesting curated selection from some interesting people.
Who might those interesting people be? I’m not that worried about getting Bill Gates to sign up (though I guess that would be cool?). I’m most interested in the niche bloggers that include book recommendations at the end of every post. Or perhaps the university lecturer that creates a reading list for their course but wants to make it publicly accessible. Maybe even startups who have a reading list for new hires? And for the Substack writers with interesting perspectives, I’d like to be able to see some of the books that helped form that viewpoint.
By deliberately avoiding a comprehensive database and ML recommendation algorithms, I’m hoping this might work without a significant time investment. In an industry where the stone has been thoroughly bled dry by you know who, this seems like pretty much the only option.
You can give it a try here: https://www.copybooks.app (and please do!). It’s completely free for now — if it seems like people like it, I’ll look into what kind of “premium” features I can add. The code is open source, though this is very much a spare time project for me, so don’t expect too much community management (I also don’t really know how to do that).
The technical bit — my verdict on Supabase
Supabase is pretty new. They bill themselves as “The Open Source Firebase Alternative” and they talk a lot about how quickly you can get up and running. They’re not wrong. It was definitely the easiest way of getting set up with authentication and a relational database that I’ve ever tried (for comparison, I had a play with Hasura earlier this year and Supabase was 10 times easier).
As with Firebase, Supabase lets you build a fairly complicated app without a server. By setting access restrictions at row level, you can directly query (and get realtime updates from) the database without needing to set up middleware to handle connections. This, combined with static site hosting, storage, out of the box authentication and serverless functions for sensitive processes (apparently coming soon for Supabase), makes both Firebase and Supabase pretty good options for getting something up and running in a weekend.
How does it rank as a Firebase alternative though? I have a few years’ experience with Firebase, and now a whole 3 days experience with Supabase, so I am at least half-well-qualified to make a judgment on the comparison. Right now, I would say that Firebase just about edges the developer experience. Their tight integration between the functions, the database and the authentication makes development very fast. The docs, examples and extensions are also much more developed (as you would expect for a mature product). Supabase is very cool, but you quite quickly run into some irritating bugs when you try do something slightly more complicated. If you’re looking to build something fairly simple quickly, and you’re comfortable with NoSQL world, Firebase will do the best job for you today.
However, I don’t think that will last long. Firebase is definitely progressing at a slower pace and has some clear limitations that I can see Supabase smashing through mostly by virtue of building on top of PostgreSQL .
For example:
Since it’s NoSQL, Firebase can’t do joins so you end up denormalising a lot, and often making multiple queries to fetch related data.
Firebase doesn’t have any GIS capabilities, so you can’t do any location based analysis.
Firebase has no way of defining a schema (you can sort of hack it together with the rules, but it’s a real ballache)
You can’t do full text search on Firebase. As a result, I tend to use Elasticsearch in combination with Firebase which can get a bit convoluted.
In my view, this is what the future looks like:

About ‘Not Fun at Parties’
Running a newsletter is pretty new for me. I’m not quite sure which direction I’m going to take it in, but my hazy plan is that post will be a mix of product/data/tech analysis and “check out this thing I’ve made”. I’m hoping it will give me an excuse to try out cool tech and write about things a particular kind of person will find interesting. If that sounds like your vibe, be sure to like and subscribe (eurgh).
Nice, what source are you using for your book api?